#llm
Read more stories on Hashnode
Articles with this tag
What is Caching? Caching is a technique used to store frequently accessed data in a temporary storage area, enabling faster retrieval and reducing the...
Intelligent systems, especially those powered by large language models (LLMs), are revolutionizing the way we interact with technology. Frameworks...
In this blog, we will look at the inner workings of LLM. Data Collection and Pre-processing LLMs are trained on large amounts of text datasets from...
To answer this, we need to understand the Transformers architecture introduced by researchers at Google DeepMind in their paper "Attention is All You...
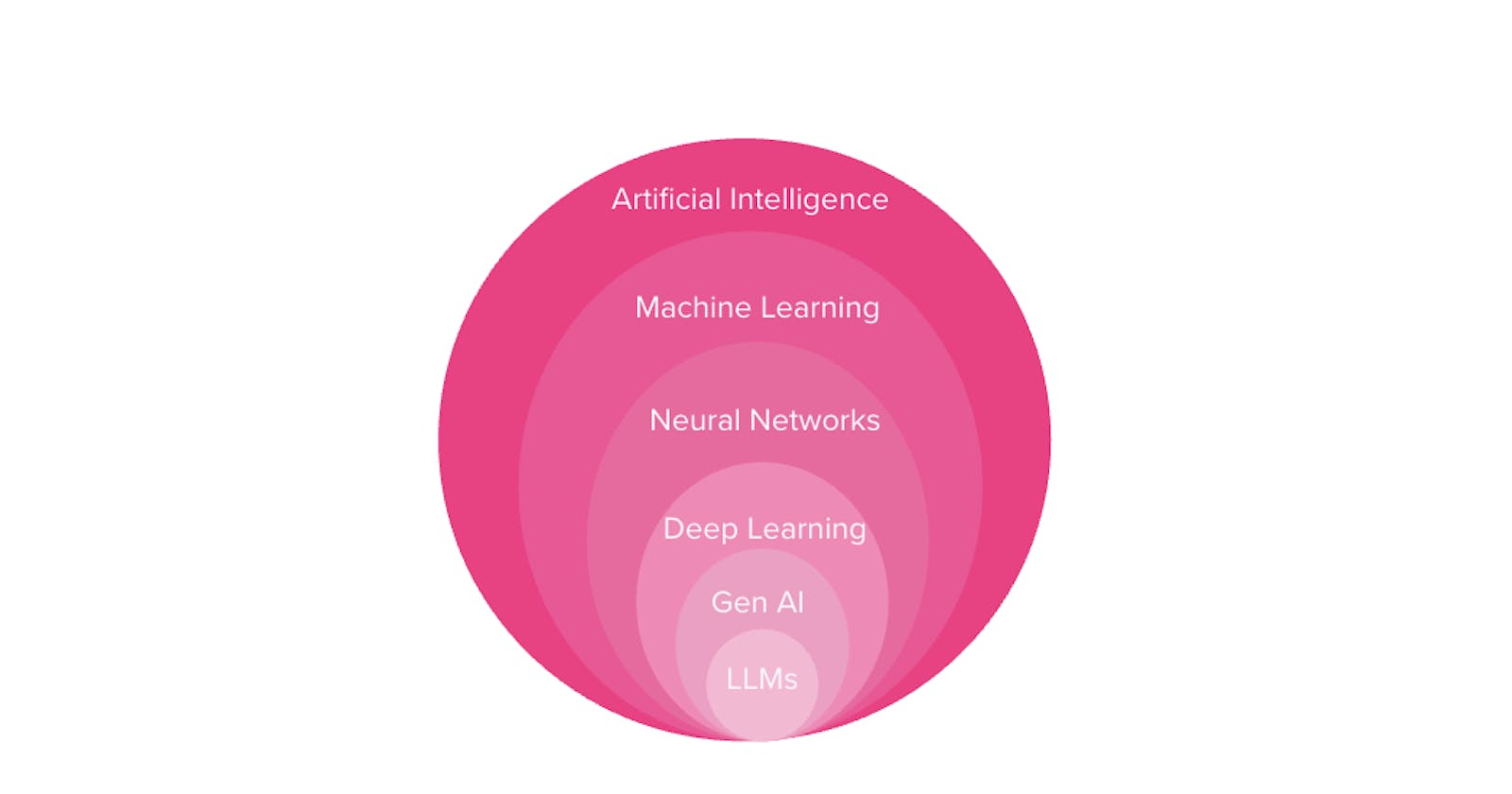
Artificial intelligence (AI) has rapidly evolved in recent years and has become an integral part of our everyday lives. In today's post, I talk about...